Crean un sistema virtual para mejorar la pronunciación
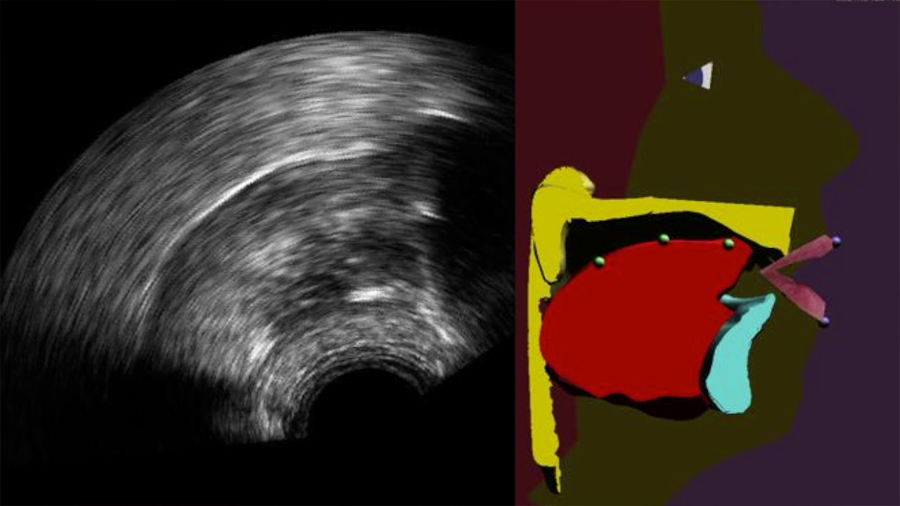
Investigadores franceses han desarrollado un sistema que permite visualizar, en tiempo real, los movimientos de nuestra lengua. Se trata de una ecografía lingual aumentada que, además de mostrar el rostro y los labios, hace aparecer la lengua, el paladar y los dientes, generalmente ocultos en el interior de la boca.
Los movimientos de la lengua son capturados con la ayuda de una sonda ecográfica situada debajo de la mandíbula, y a continuación procesados por un algoritmo de aprendizaje automático que permite pilotar una especia de “cabeza parlante articulatoria”.
Este sistema de retorno visual, que permite comprender mejor y mejorar la pronunciación humana, será de gran utilidad para la reeducación de la ortofonía o el aprendizaje de una lengua extranjera. Los resultados se publican en la revista Speech Communication.
La ortofonía hace referencia tanto a la corrección de los defectos de la voz y de la pronunciación de los sonidos de una lengua, así como a la pronunciación correcta de los sonidos de otra lengua.
La reeducación ortofónica de una persona aquejada de trastornos de la articulación se apoya en parte en la reeducación a través de ejercicios, mediante los cuales el terapeuta analiza cualitativamente la pronunciación del paciente y le explica oralmente, o con la ayuda de esquemas, cómo usar sus articulaciones, y especialmente la lengua, algo de lo que generalmente no somos conscientes.
La eficacia de la reeducación ortofónica se basa en la buena integración por el paciente de las indicaciones facilitadas por el terapeuta. Es en este momento en el que los sistemas de retorno articulatorio visual permiten al paciente visualizar en tiempo real sus propios movimientos articulatorios (especialmente los de la lengua), con la finalidad de tomar consciencia de lo que está haciendo y de corregir más rápidamente los defectos de la pronunciación.
Desde hace años, investigadores anglosajones han desarrollado la técnica de la ecografía para la concepción de sistemas de retorno visual. En estos trabajos, la imagen de la lengua es obtenida colocando bajo la mandíbula una sonda similar a la que se utiliza para obtener la imagen de un feto. Esta imagen, sin embargo, es difícil de ser aprovechada por el paciente porque no es de buena calidad y también porque no da información alguna sobre el paladar o los dientes.
Retorno visual mejorado
En el nuevo trabajo, los investigadores franceses mejoran este retorno visual a través de una especie de cabeza parlante articulatoria que es animada automáticamente en tiempo real a partir de imágenes ecográficas apoyadas con un algoritmo, según se explica en un comunicado.
Este clon virtual de una persona parlante permite una visualización del proceso físico de articulación de una lengua y su pronunciación mucho más intuitiva y contextualizada.
La fuerza del nuevo sistema, a diferencia de los anteriores, se basa en el algoritmo de aprendizaje automático (machine learning) en el que estos investigadores franceses llevan trabajando desde hace unos años.
Este algoritmo permite, dentro de ciertos límites, procesar los movimientos articulatorios que la persona no puede controlar. Este procesamiento es indispensable para aplicar las terapias ortofónicas necesarias.
Para conseguirlo, el algoritmo explota un modelo probabilista construido a partir de una gran base de datos articulatorios adquirida a través de un locutor considerado experto, capaz de pronunciar el conjunto de los sonidos de una o muchas lenguas.
Este modelo es adaptado automáticamente a la morfología de cada nuevo usuario, a través de una corta fase de adaptación del sistema, mediante la cual el paciente debe pronunciar algunas frases.
Este sistema, validado en laboratorio para personas sanas, se está testando actualmente en una versión simplificada en un estudio clínico para pacientes que han sufrido una intervención quirúrgica en su lengua.
Además, los investigadores desarrollan otra versión del sistema en la que la cabeza parlante articulatoria es animada automáticamente, no a partir de la ecografía, sino directamente a partir de la voz del usuario.
Fuente: tendencias21.net





