

Desarrolladores estadounidenses han creado un algoritmo capaz de predecir el movimiento de manos humanas en un discurso. Recibiendo solo grabaciones de audio del habla, el algoritmo crea un modelo animado del cuerpo humano y luego genera un video realista basado en él. El desarrollo se presentará en la conferencia CPVR 2019.

La principal forma de transmitir información a otras personas es el habla. Sin embargo, además de ella, también utilizamos gestos activamente en nuestra conversación, reforzando las palabras y dándoles un toque emocional.
Por cierto, de acuerdo con la hipótesis más probable del desarrollo del lenguaje humano, inicialmente los ancestros del hombre se comunicaban principalmente con gestos, pero el uso activo de las manos en la vida cotidiana condujo al desarrollo de una comunicación sólida y lo hizo básico. De una forma u otra, el proceso en el que una persona pronuncia palabras en una conversación está estrechamente relacionado con los movimientos de sus manos.
Moviendo las manos
Ahora, un equipo de investigadores dirigidos por Jitendra Malik de la Universidad de California en Berkeley utilizaron esta conexión para predecir los gestos de una persona en una conversación basada en el componente de voz de su discurso.
El trabajo del algoritmo se puede dividir en dos etapas: primero, predice el movimiento de las manos a través de la grabación de audio del habla y luego visualiza los gestos predichos utilizando el algoritmo presentado en 2018 por un grupo relacionado de investigadores. Luego, los desarrolladores enseñaron a la red neuronal a transferir el movimiento de las personas, utilizando una etapa intermedia con el reconocimiento de la postura de una persona.
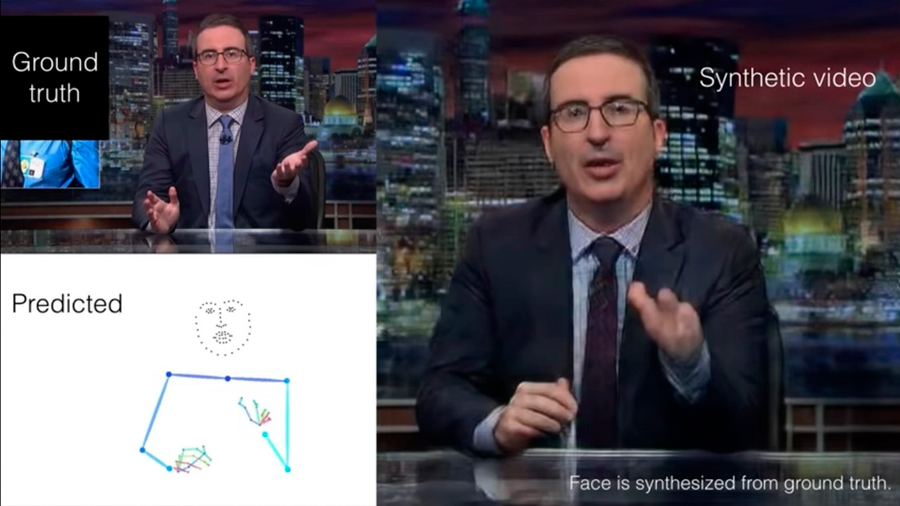
En la primera etapa, el algoritmo UNet sobre la base de la red neuronal convolucional acepta un espectrograma bidimensional de grabación de audio y lo convierte en una señal intermedia unidimensional. Esta señal se transforma en una secuencia de poses representada como un modelo esquelético con 49 puntos clave que reflejan partes de los brazos, hombros y cuello. Después de eso, la secuencia de poses se transmite al algoritmo de visualización, que lo convierte en un video.
Con el fin de enseñarle al algoritmo a convertir el habla en movimiento, los investigadores recolectaron conjuntos de datos que consistían en registros con una duración total de 144 horas. Hubo presentadores de televisión, conferencistas y predicadores religiosos en las grabaciones; tal elección se debió al hecho de que les fue fácil encontrar largas grabaciones de discursos con gesticulaciones.
Luego, usando el algoritmo OpenPose, los investigadores compararon cada cuadro del conjunto de datos con un modelo de esqueleto. Al obtener durante el entrenamiento la grabación del habla y los cuadros con el modelo terminado, el algoritmo aprendió a crear videos realistas. Cabe señalar que el enfoque elegido por los autores implica que para un trabajo correcto es necesario entrenar un modelo de red neuronal independiente para una persona específica.
Algoritmo mejorado
En el video demostrado por los investigadores se puede ver que algunos movimientos no se corresponden completamente con los movimientos reales de una persona en la grabación original. Por ejemplo, a menudo el algoritmo selecciona el movimiento correcto, pero usa la mano equivocada. Sin embargo, esto es una consecuencia de una falta fundamental de enfoque en lugar de su implementación incorrecta. El hecho es que los gestos durante el habla no son invariantes: diferentes gestos pueden corresponder a la misma frase, hablada por la misma persona.
Los investigadores realizaron una evaluación cuantitativa del algoritmo, calculando qué parte de los puntos clave en los modelos creados correspondían a la posición de los puntos obtenidos para el marco real.
El nuevo algoritmo estuvo significativamente por delante de los algoritmos similares probados en los mismos datos: 44.62% contra 39.69% del algoritmo con el mejor resultado entre los desarrollos de otros desarrolladores. Cabe destacar que la variante del nuevo algoritmo utilizado sin un discriminador recibió un resultado más alto que con un discriminador. Los autores explican esto por el hecho de que el discriminador provoca que el generador cree datos de salida más uniformes.
Recientemente, otro grupo de desarrolladores estadounidenses le enseñaron a una red neuronal a crear una imagen del rostro a partir del discurso de una persona. El algoritmo fue entrenado en un conjunto de datos que consta de millones de videos.
Fuente: nmas1.org